1.7.0 - 2025-04-11
- MLServer has now support for Python 3.11 and 3.12 by @shivakrishnaah in (#1951)
- MLServer now supports enabling assignment of models to dedicated inference pool groups to avoid risk of starvation by @RobertSamoilescu in (##2040)
- MLServer now includes compatibility with additional column types available in the MLflow runtime such as: Array, Map, Object, Any by @RobertSamoilescu in (#2080)
- Relaxing Pydantic dependencies by @lemonhead94 in (#1928)
- Adjusted the version range for FastAPI to ensure compatibility with future releases by @sergioave in (#1954)
- Forward rest parameters to model @idlefella in (#1921)
- Force clean up env fix by @sakoush in (#2029)
- PandasCodec improperly encoding columns of numeric lists fix by @RobertSamoilescu in (#2080)
- Opentelemetry dependency mismatch fix by @lawrence-c in (#2088)
- AdaptiveBatcher timeout calculation fix by @hanlaur in (#2093)
- Update CHANGELOG by @github-actions in #1905
- docs: add docs for gitbook by @sakoush in #1919
- Relaxing Pydantic dependencies by @lemonhead94 in #1928
- build(deps): Upgrade fastapi and starlette by @sakoush in #1934
- Re-generate License Info by @github-actions in #1935
- Update FastAPI version constraint by @sergioave in #1954
- Forward rest parameters to model by @idlefella in #1921
- Revert "build(deps): bump mlflow from 2.18.0 to 2.19.0 in /runtimes/mlflow" by @sakoush in #1988
- Added dependency upgrades for python3.12 support by @shivakrishnaah in #1951
- Re-generate License Info by @github-actions in #1991
- Further CI fixes for py312 support by @sakoush in #1992
- Revert "build(deps): bump python-multipart from 0.0.9 to 0.0.18 in /runtimes/alibi-detect" by @sakoush in #1994
- Re-generate License Info by @github-actions in #2027
- Force clean up env (for py 3.12) by @sakoush in #2029
- Pinned preflight to latest version by @RobertSamoilescu in #2041
- Bump gevent to 24.11.1 by @RobertSamoilescu in #2042
- Bumped python-multipart to 0.0.20 by @RobertSamoilescu in #2043
- Bumped python-multipart-0.0.20 on alibi-explain runtime by @RobertSamoilescu in #2044
- Included separate inference pool by @RobertSamoilescu in #2040
- Wrote docs for inference_pool_gid by @RobertSamoilescu in #2045
- Update lightgbm in alibi runtime to 4.6 by @sakoush in #2081
- Fix pandas codec by @RobertSamoilescu in #2080
- Fix interceptors insert tuple -> list by @lawrence-c in #2088
- Fix AdaptiveBatcher timeout calculation by @hanlaur in #2093
- Fix onnxruntime version by @RobertSamoilescu in #2100
- Included labels for preflight checks by @RobertSamoilescu in #2101
- Bumped poetry to 2.1.1 by @RobertSamoilescu in #2103
- Add installation for poetry export plugin by @RobertSamoilescu in #2104
- ci: Merge change for release 1.7.0 [4] by @RobertSamoilescu in #2107
- @lemonhead94 made their first contribution in #1928
- @sergioave made their first contribution in #1954
- @shivakrishnaah made their first contribution in #1951
- @lawrence-c made their first contribution in #2088
- @hanlaur made their first contribution in #2093
Full Changelog: https://github.com/SeldonIO/MLServer/compare/1.6.1...1.7.0
1.6.1 - 2024-09-10
MLServer now offers an option to use pre-existing Python environments by specifying a path to the environment to be used - by @idlefella in (#1891)
MLServer released catboost runtime which allows serving catboost models with MLServer - by @sakoush in (#1839)
- Kafka json byte encoding fix to match rest server by @DerTiedemann and @sakoush in (#1622)
- Prometheus interceptor fix for gRPC streaming by @RobertSamoilescu in (#1858)
- Re-generate License Info by @github-actions in #1812
- Update CHANGELOG by @github-actions in #1830
- Update release.yml to include catboost by @sakoush in #1839
- Fix kafka json byte encoding to match rest server by @DerTiedemann in #1622
- Included Prometheus interceptor support for gRPC streaming by @RobertSamoilescu in #1858
- Run gRPC test serially by @RobertSamoilescu in #1872
- Re-generate License Info by @github-actions in #1886
- Feature/support existing environments by @idlefella in #1891
- Fix tensorflow upperbound macos by @RobertSamoilescu in #1901
- ci: Merge change for release 1.6.1 by @RobertSamoilescu in #1902
- Bump preflight to 1.10.0 by @RobertSamoilescu in #1903
- ci: Merge change for release 1.6.1 [2] by @RobertSamoilescu in #1904
- @DerTiedemann made their first contribution in #1622
- @idlefella made their first contribution in #1891
Full Changelog: https://github.com/SeldonIO/MLServer/compare/1.6.0...1.6.1
1.6.0 - 2024-06-26
MLServer supports Pydantic V2.
MLServer supports streaming data to and from your models.
Streaming support is available for both the REST and gRPC servers:
- for the REST server is limited only to server streaming. This means that the client sends a single request to the server, and the server responds with a stream of data.
- for the gRPC server is available for both client and server streaming. This means that the client sends a stream of data to the server, and the server responds with a stream of data.
See our docs and example for more details.
- fix(ci): fix typo in CI name by @sakoush in #1623
- Update CHANGELOG by @github-actions in #1624
- Re-generate License Info by @github-actions in #1634
- Fix mlserver_huggingface settings device type by @geodavic in #1486
- fix: Adjust HF tests post-merge of PR #1486 by @sakoush in #1635
- Update README.md w licensing clarification by @paulb-seldon in #1636
- Re-generate License Info by @github-actions in #1642
- fix(ci): optimise disk space for GH workers by @sakoush in #1644
- build: Update maintainers by @jesse-c in #1659
- fix: Missing f-string directives by @jesse-c in #1677
- build: Add Catboost runtime to Dependabot by @jesse-c in #1689
- Fix JSON input shapes by @ReveStobinson in #1679
- build(deps): bump alibi-detect from 0.11.5 to 0.12.0 by @jesse-c in #1702
- build(deps): bump alibi from 0.9.5 to 0.9.6 by @jesse-c in #1704
- Docs correction - Updated README.md in mlflow to match column names order by @vivekk0903 in #1703
- fix(runtimes): Remove unused Pydantic dependencies by @jesse-c in #1725
- test: Detect generate failures by @jesse-c in #1729
- build: Add granularity in types generation by @jesse-c in #1749
- Migrate to Pydantic v2 by @jesse-c in #1748
- Re-generate License Info by @github-actions in #1753
- Revert "build(deps): bump uvicorn from 0.28.0 to 0.29.0" by @jesse-c in #1758
- refactor(pydantic): Remaining migrations for deprecated functions by @jesse-c in #1757
- Fixed openapi dataplane.yaml by @RobertSamoilescu in #1752
- fix(pandas): Use Pydantic v2 compatible type by @jesse-c in #1760
- Fix Pandas codec decoding from numpy arrays by @lhnwrk in #1751
- build: Bump versions for Read the Docs by @jesse-c in #1761
- docs: Remove quotes around local TOC by @jesse-c in #1764
- Spawn worker in custom environment by @lhnwrk in #1739
- Re-generate License Info by @github-actions in #1767
- basic contributing guide on contributing and opening a PR by @bohemia420 in #1773
- Inference streaming support by @RobertSamoilescu in #1750
- Re-generate License Info by @github-actions in #1779
- build: Lock GitHub runners' OS by @jesse-c in #1765
- Removed text-model form benchmarking by @RobertSamoilescu in #1790
- Bumped mlflow to 2.13.1 and gunicorn to 22.0.0 by @RobertSamoilescu in #1791
- Build(deps): Update to poetry version 1.8.3 in docker build by @sakoush in #1792
- Bumped werkzeug to 3.0.3 by @RobertSamoilescu in #1793
- Docs streaming by @RobertSamoilescu in #1789
- Bump uvicorn 0.30.1 by @RobertSamoilescu in #1795
- Fixes for all-runtimes by @RobertSamoilescu in #1794
- Fix BaseSettings import for pydantic v2 by @RobertSamoilescu in #1798
- Bumped preflight version to 1.9.7 by @RobertSamoilescu in #1797
- build: Install dependencies only in Tox environments by @jesse-c in #1785
- Bumped to 1.6.0.dev2 by @RobertSamoilescu in #1803
- Fix CI/CD macos-huggingface by @RobertSamoilescu in #1805
- Fixed macos kafka CI by @RobertSamoilescu in #1807
- Update poetry lock by @RobertSamoilescu in #1808
- Re-generate License Info by @github-actions in #1813
- Fix/macos all runtimes by @RobertSamoilescu in #1823
- fix: Update stale reviewer in licenses.yml workflow by @sakoush in #1824
- ci: Merge changes from master to release branch by @sakoush in #1825
- @paulb-seldon made their first contribution in #1636
- @ReveStobinson made their first contribution in #1679
- @vivekk0903 made their first contribution in #1703
- @RobertSamoilescu made their first contribution in #1752
- @lhnwrk made their first contribution in #1751
- @bohemia420 made their first contribution in #1773
Full Changelog: https://github.com/SeldonIO/MLServer/compare/1.5.0...1.6.0
1.5.0 - 2024-03-05
- Update CHANGELOG by @github-actions in #1592
- build: Migrate away from Node v16 actions by @jesse-c in #1596
- build: Bump version and improve release doc by @jesse-c in #1602
- build: Upgrade stale packages (fastapi, starlette, tensorflow, torch) by @sakoush in #1603
- fix(ci): tests and security workflow fixes by @sakoush in #1608
- Re-generate License Info by @github-actions in #1612
- fix(ci): Missing quote in CI test for all_runtimes by @sakoush in #1617
- build(docker): Bump dependencies by @jesse-c in #1618
- docs: List supported Python versions by @jesse-c in #1591
- fix(ci): Have separate smaller tasks for release by @sakoush in #1619
- We remove support for python 3.8, check #1603 for more info. Docker images for mlserver are already using python 3.10.
Full Changelog: https://github.com/SeldonIO/MLServer/compare/1.4.0...1.5.0
1.4.0 - 2024-02-28
- Free up some space for GH actions by @adriangonz in #1282
- Introduce tracing with OpenTelemetry by @vtaskow in #1281
- Update release CI to use Poetry by @adriangonz in #1283
- Re-generate License Info by @github-actions in #1284
- Add support for white-box explainers to alibi-explain runtime by @ascillitoe in #1279
- Update CHANGELOG by @github-actions in #1294
- Fix build-wheels.sh error when copying to output path by @lc525 in #1286
- Fix typo by @strickvl in #1289
- feat(logging): Distinguish logs from different models by @vtaskow in #1302
- Make sure we use our Response class by @adriangonz in #1314
- Adding Quick-Start Guide to docs by @ramonpzg in #1315
- feat(logging): Provide JSON-formatted structured logging as option by @vtaskow in #1308
- Bump in conda version and mamba solver by @dtpryce in #1298
- feat(huggingface): Merge model settings by @jesse-c in #1337
- feat(huggingface): Load local artefacts in HuggingFace runtime by @vtaskow in #1319
- Document and test behaviour around NaN by @adriangonz in #1346
- Address flakiness on 'mlserver build' tests by @adriangonz in #1363
- Bump Poetry and lockfiles by @adriangonz in #1369
- Bump Miniforge3 to 23.3.1 by @adriangonz in #1372
- Re-generate License Info by @github-actions in #1373
- Improved huggingface batch logic by @ajsalow in #1336
- Add inference params support to MLFlow's custom invocation endpoint (… by @M4nouel in #1375
- Increase build space for runtime builds by @adriangonz in #1385
- Fix minor typo in
sklearnREADME by @krishanbhasin-gc in #1402 - Add catboost classifier support by @krishanbhasin-gc in #1403
- added model_kwargs to huggingface model by @nanbo-liu in #1417
- Re-generate License Info by @github-actions in #1456
- Local response cache implementation by @SachinVarghese in #1440
- fix link to custom runtimes by @kretes in #1467
- Improve typing on
Environmentclass by @krishanbhasin-gc in #1469 - build(dependabot): Change reviewers by @jesse-c in #1548
- MLServer changes from internal fork - deps and CI updates by @sakoush in #1588
- @vtaskow made their first contribution in #1281
- @lc525 made their first contribution in #1286
- @strickvl made their first contribution in #1289
- @ramonpzg made their first contribution in #1315
- @jesse-c made their first contribution in #1337
- @ajsalow made their first contribution in #1336
- @M4nouel made their first contribution in #1375
- @nanbo-liu made their first contribution in #1417
- @kretes made their first contribution in #1467
Full Changelog: https://github.com/SeldonIO/MLServer/compare/1.3.5...1.4.0
1.3.5 - 2023-07-10
- Rename HF codec to
hfby @adriangonz in #1268 - Publish is_drift metric to Prom by @joshsgoldstein in #1263
- @joshsgoldstein made their first contribution in #1263
Full Changelog: https://github.com/SeldonIO/MLServer/compare/1.3.4...1.3.5
1.3.4 - 2023-06-21
- Silent logging by @dtpryce in #1230
- Fix
mlserver inferwithBYTESby @RafalSkolasinski in #1213
Full Changelog: https://github.com/SeldonIO/MLServer/compare/1.3.3...1.3.4
1.3.3 - 2023-06-05
- Add default LD_LIBRARY_PATH env var by @adriangonz in #1120
- Adding cassava tutorial (mlserver + seldon core) by @edshee in #1156
- Add docs around converting to / from JSON by @adriangonz in #1165
- Document SKLearn available outputs by @adriangonz in #1167
- Fix minor typo in
alibi-explaintests by @ascillitoe in #1170 - Add support for
.ubjmodels and improve XGBoost docs by @adriangonz in #1168 - Fix content type annotations for pandas codecs by @adriangonz in #1162
- Added option to configure the grpc histogram by @cristiancl25 in #1143
- Add OS classifiers to project's metadata by @adriangonz in #1171
- Don't use
qsizefor parallel worker queue by @adriangonz in #1169 - Fix small typo in Python API docs by @krishanbhasin-gc in #1174
- Fix star import in
mlserver.codecs.*by @adriangonz in #1172
- @cristiancl25 made their first contribution in #1143
- @krishanbhasin-gc made their first contribution in #1174
Full Changelog: https://github.com/SeldonIO/MLServer/compare/1.3.2...1.3.3
1.3.2 - 2023-05-10
- Use default initialiser if not using a custom env by @adriangonz in #1104
- Add support for online drift detectors by @ascillitoe in #1108
- added intera and inter op parallelism parameters to the hugggingface … by @saeid93 in #1081
- Fix settings reference in runtime docs by @adriangonz in #1109
- Bump Alibi libs requirements by @adriangonz in #1121
- Add default LD_LIBRARY_PATH env var by @adriangonz in #1120
- Ignore both .metrics and .envs folders by @adriangonz in #1132
- @ascillitoe made their first contribution in #1108
Full Changelog: https://github.com/SeldonIO/MLServer/compare/1.3.1...1.3.2
1.3.1 - 2023-04-27
- Move OpenAPI schemas into Python package (#1095)
1.3.0 - 2023-04-27
WARNING
⚠️ : The1.3.0has been yanked from PyPi due to a packaging issue. This should have been now resolved in>= 1.3.1.
More often that not, your custom runtimes will depend on external 3rd party dependencies which are not included within the main MLServer package - or different versions of the same package (e.g. scikit-learn==1.1.0 vs scikit-learn==1.2.0). In these cases, to load your custom runtime, MLServer will need access to these dependencies.
In MLServer 1.3.0, it is now possible to load this custom set of dependencies by providing them, through an environment tarball, whose path can be specified within your model-settings.json file. This custom environment will get provisioned on the fly after loading a model - alongside the default environment and any other custom environments.
Under the hood, each of these environments will run their own separate pool of workers.

The MLServer framework now includes a simple interface that allows you to register and keep track of any custom metrics:
[mlserver.register()](https://mlserver.readthedocs.io/en/latest/reference/api/metrics.html#mlserver.register): Register a new metric.[mlserver.log()](https://mlserver.readthedocs.io/en/latest/reference/api/metrics.html#mlserver.log): Log a new set of metric / value pairs.
Custom metrics will generally be registered in the [load()](https://mlserver.readthedocs.io/en/latest/reference/api/model.html#mlserver.MLModel.load) method and then used in the [predict()](https://mlserver.readthedocs.io/en/latest/reference/api/model.html#mlserver.MLModel.predict) method of your custom runtime. These metrics can then be polled and queried via Prometheus.

MLServer 1.3.0 now includes an autogenerated Swagger UI which can be used to interact dynamically with the Open Inference Protocol.
The autogenerated Swagger UI can be accessed under the /v2/docs endpoint.
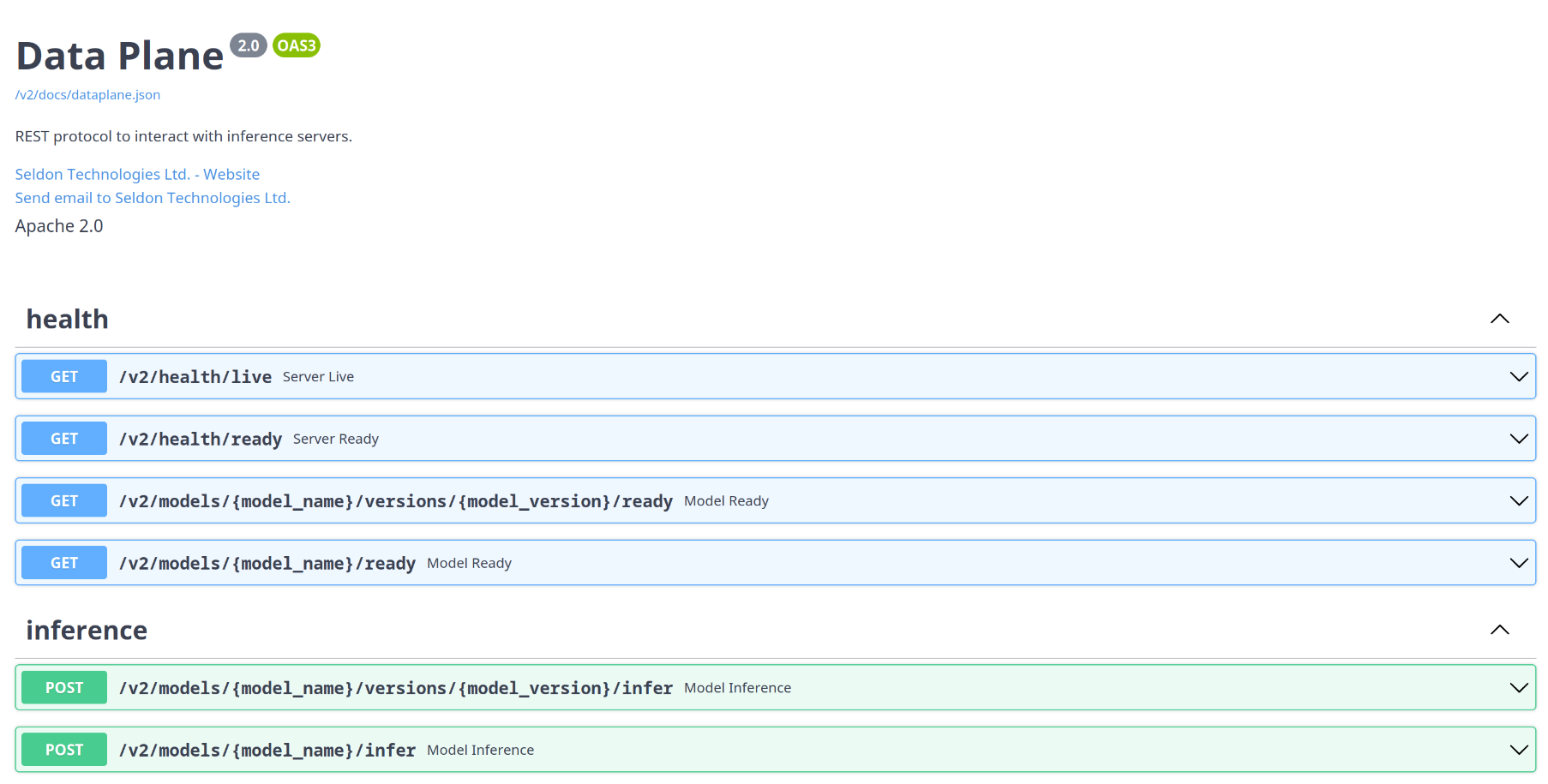
Alongside the general API documentation, MLServer also exposes now a set of API docs tailored to individual models, showing the specific endpoints available for each one.
The model-specific autogenerated Swagger UI can be accessed under the following endpoints:
/v2/models/{model_name}/docs/v2/models/{model_name}/versions/{model_version}/docs
MLServer now includes improved Codec support for all the main different types that can be returned by HugginFace models - ensuring that the values returned via the Open Inference Protocol are more semantic and meaningful.
Massive thanks to @pepesi for taking the lead on improving the HuggingFace runtime!
Internally, MLServer leverages a Model Repository implementation which is used to discover and find different models (and their versions) available to load. The latest version of MLServer will now allow you to swap this for your own model repository implementation - letting you integrate against your own model repository workflows.
This is exposed via the model_repository_implementation flag of your settings.json configuration file.
Thanks to @jgallardorama (aka @jgallardorama-itx ) for his effort contributing this feature!
MLServer 1.3.0 introduces a new set of metrics to increase visibility around two of its internal queues:
- Adaptive batching queue: used to accumulate request batches on the fly.
- Parallel inference queue: used to send over requests to the inference worker pool.
Many thanks to @alvarorsant for taking the time to implement this highly requested feature!
The latest version of MLServer includes a few optimisations around image size, which help reduce the size of the official set of images by more than ~60% - making them more convenient to use and integrate within your workloads. In the case of the full seldonio/mlserver:1.3.0 image (including all runtimes and dependencies), this means going from 10GB down to ~3GB.
Alongside its built-in inference runtimes, MLServer also exposes a Python framework that you can use to extend MLServer and write your own codecs and inference runtimes. The MLServer official docs now include a reference page documenting the main components of this framework in more detail.
- @rio made their first contribution in #864
- @pepesi made their first contribution in #692
- @jgallardorama made their first contribution in #849
- @alvarorsant made their first contribution in #860
- @gawsoftpl made their first contribution in #950
- @stephen37 made their first contribution in #1033
- @sauerburger made their first contribution in #1064
1.2.4 - 2023-03-10
Full Changelog: https://github.com/SeldonIO/MLServer/compare/1.2.3...1.2.4
1.2.3 - 2023-01-16
Full Changelog: https://github.com/SeldonIO/MLServer/compare/1.2.2...1.2.3
1.2.2 - 2023-01-16
Full Changelog: https://github.com/SeldonIO/MLServer/compare/1.2.1...1.2.2
1.2.1 - 2022-12-19
Full Changelog: https://github.com/SeldonIO/MLServer/compare/1.2.0...1.2.1
1.2.0 - 2022-11-25
MLServer now exposes an alternative “simplified” interface which can be used to write custom runtimes. This interface can be enabled by decorating your predict() method with the mlserver.codecs.decode_args decorator, and it lets you specify in the method signature both how you want your request payload to be decoded and how to encode the response back.
Based on the information provided in the method signature, MLServer will automatically decode the request payload into the different inputs specified as keyword arguments. Under the hood, this is implemented through MLServer’s codecs and content types system.
from mlserver import MLModel
from mlserver.codecs import decode_args
class MyCustomRuntime(MLModel):
async def load(self) -> bool:
# TODO: Replace for custom logic to load a model artifact
self._model = load_my_custom_model()
self.ready = True
return self.ready
@decode_args
async def predict(self, questions: List[str], context: List[str]) -> np.ndarray:
# TODO: Replace for custom logic to run inference
return self._model.predict(questions, context)To make it easier to write your own custom runtimes, MLServer now ships with a mlserver init command that will generate a templated project. This project will include a skeleton with folders, unit tests, Dockerfiles, etc. for you to fill.

MLServer now lets you load custom runtimes dynamically into a running instance of MLServer. Once you have your custom runtime ready, all you need to do is to move it to your model folder, next to your model-settings.json configuration file.
For example, if we assume a flat model repository where each folder represents a model, you would end up with a folder structure like the one below:
.
├── models
│ └── sum-model
│ ├── model-settings.json
│ ├── models.py
This release of MLServer introduces a new mlserver infer command, which will let you run inference over a large batch of input data on the client side. Under the hood, this command will stream a large set of inference requests from specified input file, arrange them in microbatches, orchestrate the request / response lifecycle, and will finally write back the obtained responses into output file.
The 1.2.0 release of MLServer, includes a number of fixes around the parallel inference pool focused on improving the architecture to optimise memory usage and reduce latency. These changes include (but are not limited to):
- The main MLServer process won’t load an extra replica of the model anymore. Instead, all computing will occur on the parallel inference pool.
- The worker pool will now ensure that all requests are executed on each worker’s AsyncIO loop, thus optimising compute time vs IO time.
- Several improvements around logging from the inference workers.
MLServer has now dropped support for Python 3.7. Going forward, only 3.8, 3.9 and 3.10 will be supported (with 3.8 being used in our official set of images).
The official set of MLServer images has now moved to use UBI 9 as a base image. This ensures support to run MLServer in OpenShift clusters, as well as a well-maintained baseline for our images.
In line with MLServer’s close relationship with the MLflow team, this release of MLServer introduces support for the recently released MLflow 2.0. This introduces changes to the drop-in MLflow “scoring protocol” support, in the MLflow runtime for MLServer, to ensure it’s aligned with MLflow 2.0.
MLServer is also shipped as a dependency of MLflow, therefore you can try it out today by installing MLflow as:
$ pip install mlflow[extras]To learn more about how to use MLServer directly from the MLflow CLI, check out the MLflow docs.
- @johnpaulett made their first contribution in #633
- @saeid93 made their first contribution in #711
- @RafalSkolasinski made their first contribution in #720
- @dumaas made their first contribution in #742
- @Salehbigdeli made their first contribution in #776
- @regen100 made their first contribution in #839
Full Changelog: https://github.com/SeldonIO/MLServer/compare/1.1.0...1.2.0